The Retrieval Paradox: Why Your Most Productive AI Tool Is Also Your Biggest Security Risk
Every engineering team running AI agents is about to build the same thing. Some already have.
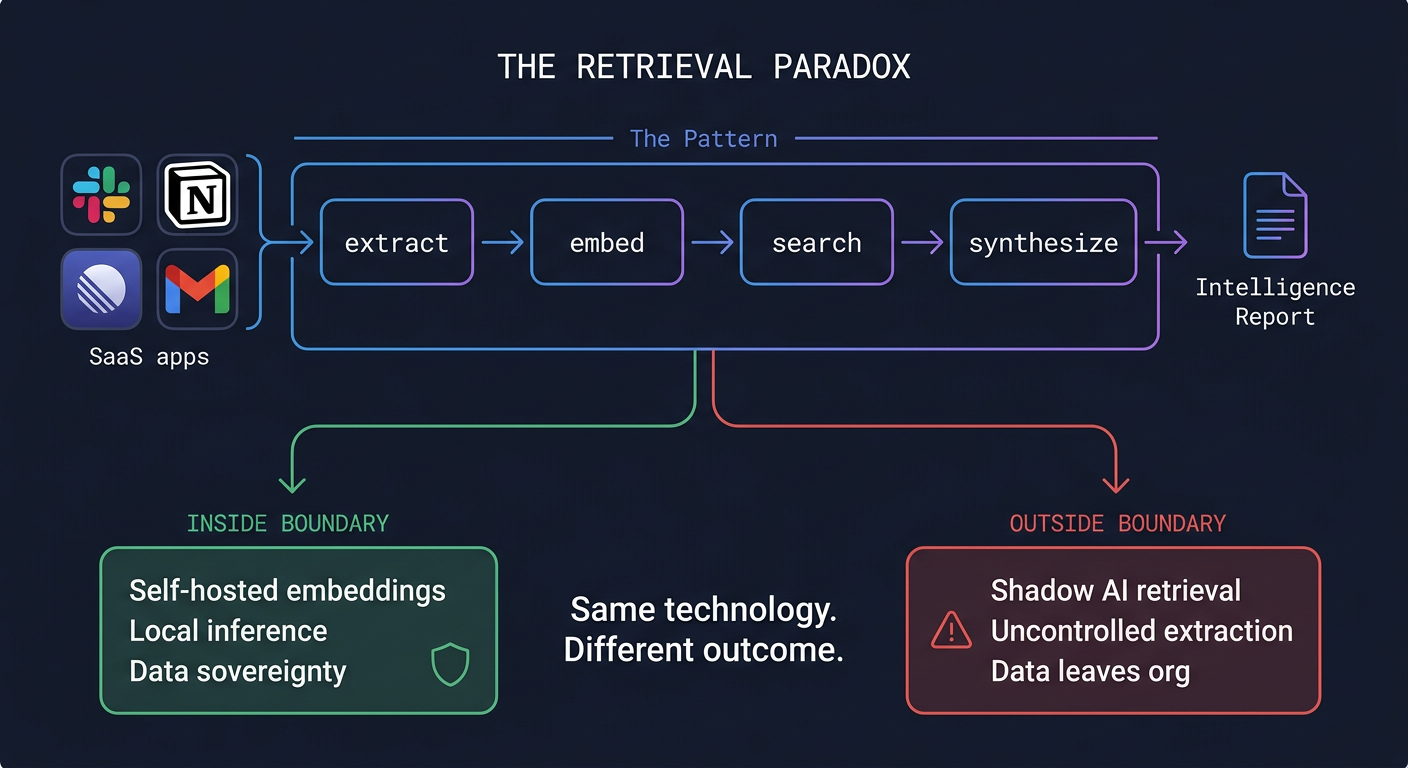
The pattern is obvious once you need it: connect to your corporate SaaS tools, extract the content, embed it, make it searchable. I built exactly this for my own agent infrastructure. Two open-source repos and a Mac Studio. Slack, Notion, Linear, Gmail, all synced locally, indexed with hybrid semantic search, queryable by any agent in the fleet.
It’s one of the most productive tools I’ve ever built. It’s also, if you think about it for more than a few seconds, a purpose-built data exfiltration system.
That tension is the interesting part. Not because the technology is new (enterprise search has existed for decades), but because the economics and accessibility have shifted so dramatically that the security implications are fundamentally different now.
The build-vs-buy gap is collapsing
Glean charges enterprise pricing for exactly this capability: index your corporate systems, let people search across all of them. Notion AI does something similar within its ecosystem. These are good products. They work.
But the core of what they do, scrape data from connected systems, generate embeddings, provide search, runs on consumer hardware now. SOTA embedding models are freely available. Apple Silicon handles them natively. You generate embeddings once (real cost, but one-time), and after that retrieval is essentially free. Vector similarity against a local SQLite database.
The building blocks are just sitting there. And the gap between “build it yourself” and “buy it” keeps narrowing.
Where it gets really interesting is the layer on top. Search finds documents. But my system doesn’t just search. An agent spawns, runs dozens of queries across every index, cross-references what it finds in Slack against the Notion spec against the Linear ticket against the email thread, and produces a comprehensive cited report. Any topic across the entire organizational history, in about 7 minutes.
An engineer on my team read the output and said it was “impossible for a human to reproduce manually.”
Glean doesn’t do that. Notion AI doesn’t do that. The commercial products are optimized for search. The self-hosted version, because it’s just an agent skill running locally, can be extended into synthesis, research, planning, whatever you need. The constraint isn’t the retrieval infrastructure. It’s your imagination about what to do with it.
This is the part the stock market hasn’t priced in. SaaS companies that leaned into AI have been rewarded while traditional SaaS gets punished. The thesis: AI-forward companies are safe. But if the AI part is the easy part to replicate, and what comes after search is even easier to build yourself than search was, the “safe” companies might be the next ones facing pressure.
The security problem nobody’s talking about
Here’s where the two threads converge.
Every team that builds self-hosted retrieval (and they will, because the productivity gains are enormous) creates an uncontrolled data extraction pipeline. Not maliciously. These are well-intentioned engineers trying to give their AI agents organizational context. But the system they build will continuously extract all content from connected SaaS tools and store it on another computer.
If you described this architecture to a CISO without the “productivity tool” framing, you’d describe a threat actor’s dream: automated, continuous extraction of all organizational knowledge from every connected system, with an AI synthesis layer that can produce intelligence briefings on any topic the organization has ever discussed.
Shadow IT has always been a headache. Shadow AI retrieval is a different category of risk entirely. A developer spinning up an unauthorized Jira instance is annoying. A developer building a system that continuously mirrors all of Slack, Notion, and Gmail to a local machine and then lets an AI agent synthesize any of it on demand? That’s a data sovereignty event.
And you can’t solve it by banning the pattern. The productivity advantages are too significant. Engineers will build it whether security signs off or not. The retrieval architecture is obvious, the tools are freely available, and the payoff is immediate.
The real question
The answer isn’t “don’t build retrieval.” The answer is deciding where the data lives and who controls the infrastructure.
Self-hosted embeddings. Local inference. Data that never crosses trust boundaries. No SaaS vendor seeing your internal communications. That’s not a feature request for some future product. It’s achievable right now, on hardware that sits under a desk.
The question for enterprise leaders isn’t whether their teams will build AI retrieval over corporate data. They will. The question is whether the organization provides a path that keeps data within corporate boundaries, or whether it happens in the shadows.
For security teams, the priority should be understanding what already exists. How many engineers on your team have already connected an AI tool to corporate SaaS APIs? How many have local copies of Slack exports or Notion databases sitting on laptops? The answer is almost certainly more than you think.
For SaaS companies, the priority should be understanding what they’re actually selling. If the core retrieval capability is replicable on consumer hardware in a weekend, the moat has to be everything else: compliance, support, integrations, the enterprise wrapper. The retrieval itself isn’t the product anymore.
And for engineering teams already building this: think carefully about where the data lands. The most useful tool you build this year might also be the one your security team would most want to know about.
This is the paradox of AI retrieval in 2026. The technology is too useful to prevent and too powerful to ignore. The organizations that figure out how to embrace it within proper boundaries will have a genuine advantage. The ones that pretend it isn’t happening will discover it’s been happening all along.